计算物理光学课题组服务器使用指南
写在前面:
这是一篇帮助你使用课题组计算服务器的指南。第一部分是基础方法,它会帮助你简单利用课题组丰富的硬件资源完成你所需要的科学计算或大型仿真,如果你在这一阶段遇到了难以解决的问题,请咨询课题组服务器管理员,他们通常能给你不少有用的建议;第二部分是进阶方法,它会帮助你通过配置服务器参数,来更高效率地使用这些硬件资源,如果你在这一阶段遇到了棘手的问题,请发挥自己的探索精神,尽力解决它吧!
概览
Q1:什么是服务器?
A1:简单来说,服务器是一种比你的办公电脑运行更快、配置更高、价格更贵的计算机。它们通常有两种组织形式,一是通过远程桌面或其它远程连接方式连接到单个服务器,这与你在自己的计算机上执行计算很相像,不同的只是你需要把你的计算文件复制到服务器上运行;二是由多台服务器组成计算集群,你一般需要远程连接到管理节点,并使用集群的调度脚本将你的计算任务分配给各个计算节点。这两种方式各有优劣,更推荐你学习使用第二种形式。
Q2:我可以使用到哪些服务器?
A2:截止到2024年4月,课题组可用的计算服务器共17台,其中2台作为不同计算集群的管理和存储节点,1台为“云端光学仿真平台”测试服务器,2台为搭载不同型号的GPU服务器。计算服务器总可用CPU核心数约1200个,总可用内存超过8TB,每台计算服务器的配置各不相同,请移步《计算物理光学课题组服务器配置一览表》查看并选择适合你使用场景的服务器。
Q3:我该如何使用这些服务器?
A3:只要你身处华中科技大学校内并连接到校园网,或通过校园VPN连接到校内的某台计算机,你就可以使用课题组所有的服务器,连接需要的用户名和密码,请联系服务器管理员。以下是服务器名称和连接方式(RDP是远程桌面):
下面是不承担计算服务的特殊服务器的连接方式,如果你需要使用,请联系服务器管理员。
基础使用方法
使用远程桌面连接到服务器
打开你的办公电脑,搜索“远程桌面连接”;
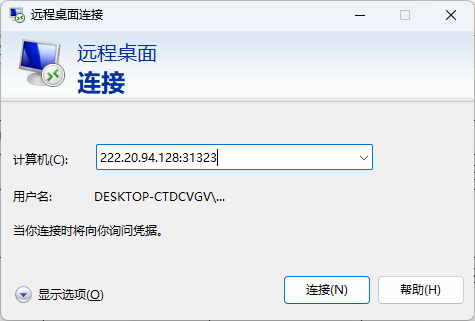
输入你所要连接的服务器的地址,例如“222.20.94.128:31323”,单击“连接”,输入服务器管理员给你的用户名和密码。注意:仅有连接方式是“RDP”的服务器才可以使用这种方式连接。
把你需要计算的文件,如“calculate.m”,"calculate.mph","calculate.fsp"等,复制到服务器上,打开运行即可。注意:不要在远程服务器的桌面上存放任何大型文件!
使用命令行连接到服务器
这种方式看上去并不友好,但更推荐你学习使用这种方式!
下载安装支持SSH连接的软件,如“XShell”,“MoBaXterm”,“Putty”等,在网络磁盘中有“MobaXterm”的安装包(/file/public/Softwares/MobaXterm23.4.zip),推荐你使用。
新建一个连接,输入服务器地址和端口。
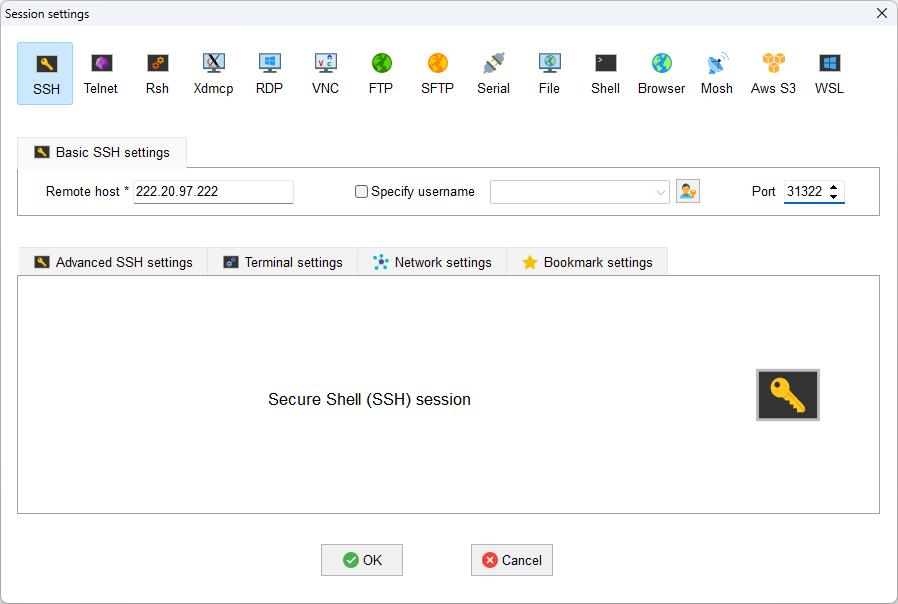
输入服务器管理员提供给你的用户名和密码,以下是一些简单的命令:
ls -al # 查看当前文件夹下有哪些文件
cd ComsolModel # 进入当前文件夹下名为“ComsolModel”的文件夹
cat slurmsubmit.sh # 查看名为“slurmsubmit.sh”文件的内容下面是示例运行结果。
有关更多的Linux命令,请询问Chat GPT,它在大多数情况下是更好的老师。
使用命令行进行科学计算的集群作业
首先你需要登录到集群的管理节点,下面是Slurm集群的一些基本命令。
sinfo # 查看当前计算节点状态
squeue # 查看当前集群调度队列状态
sbatch calculate.sh # 提交名为“calculate.sh”的集群作业脚本
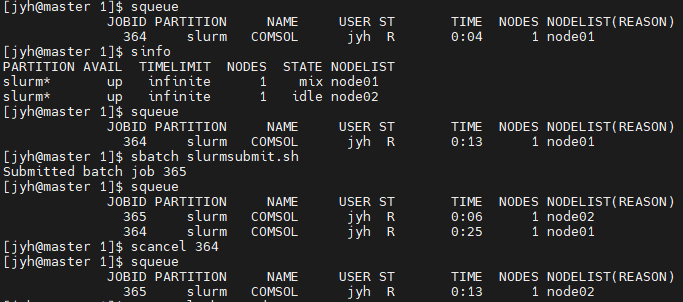
scancel jobid # 取消名为“jobid”的计算任务下面是执行示例。首先使用“sinfo”查看到计算服务器node01处于“mix”运算状态,计算服务器“node02”处于“idle”,即可用状态;然后使用"squeue"查看到当前队列有一个任务正在运行,于是提交了另一个计算任务,输出显示它的编号的“365”;使用“squeue”命令查看到编号为"365"的任务已经正在运行。最后使用“scancel”取消了编号为“364”的计算任务。
关于PBS计算集群相应的命令是
pbsnodes # 查看当前计算节点状态
qstat # 查看当前作业情况
qsub calculate.pbs # 提交名为“calculate.pbs"的集群作业脚本
qdel jobid # 取消名为“jobid”的计算任务以下两种使用方法均可:
将作业脚本“.sh”或".pbs"文件和你要计算的".m"或“.mph”文件放在相同的目录下,将脚本中的内容修改为你的需求,如“使用核数”,“内存限制”,“文件名”。
或只更改作业脚本,但需要将文件名改为你要计算的文件的绝对路径。
下面是利用Slurm和PBS进行MATLAB和COMSOL作业的示例脚本。
# 使用Slurm集群进行MATLAB作业
#!/bin/bash
#SBATCH --job-name=matlab # 作业名
#SBATCH --partition=slurm # 选择要提交的分区 slurm / gpu
#SBATCH --nodes=1 # 节点数
#SBATCH --ntasks-per-node=1 # 每节点进程数
#SBATCH --cpus-per-task=36 # 每进程占用核数
#SBATCH --mem=400G # 每节点内存限制
#SBATCH --output=output_%j.txt # 标准输出文件,%j 会被替换成作业编号
#SBATCH --error=error_%j.txt # 标准错误文件,%j 会被替换成作业编号
# SBATCH --exclusive # 请求独占访问节点
# SBATCH --gres=gpu:8 # 请求使用的 GPU 数量
# 定义MATLAB脚本的路径
MATLAB_SCRIPT_PATH="test.m"
# 运行MATLAB脚本
matlab -nodisplay -nosplash -nodesktop -r "run('${MATLAB_SCRIPT_PATH}');exit;"# 使用Slurm集群进行COMSOL作业
#!/bin/bash
#SBATCH -J COMSOL # 作业名
#SBATCH -p slurm # 队列名
#SBATCH -N 1 # 节点数
#SBATCH --ntasks-per-node=1 # 每节点进程数
#SBATCH --cpus-per-task=36 # 每进程占用核数
#SBATCH --mem=400G # 每节点内存限制
#SBATCH -o %j.out # 标准输出
#SBATCH -e %j.err # 错误日志
#SBATCH --account="${USER}"
export PATH=/public/apps/comsol60/multiphysics/bin:$PATH
INPUTFILE=Si50by50_v2.mph
OUTPUTFILE=output_Si50by50_v2.mph
BATCHLOG=job$SLURM_JOB_ID.log
comsol batch slurm -inputfile ${INPUTFILE} -outputfile ${OUTPUTFILE} -batchlog ${BATCHLOG} -prefermph -recover# 使用PBS集群进行MATLAB作业
#!/bin/sh
#PBS -N matlab_pbs # 作业名
#PBS -l nodes=node04:ppn=96 # 要占用的计算节点和核数
#PBS -q buhan # 队列名
#PBS -V
#PBS -S /bin/bash
# 指定需要运行的文件
export input_file="test_svd_matrix.m"
cat $PBS_NODEFILE
NP= `cat $PBS_NODEFILE | wc -l`
cd $PBS_O_WORKDIR
matlab -nodisplay -r "run('${input_file}'); exit;"
# 删除临时文件
rm -f /tmp/nodes.$$# 使用PBS集群进行COMSOL作业
#!/bin/sh
#PBS -N comsol_pbs # 作业名
#PBS -l nodes=node03:ppn=64 # 要占用的计算节点和核数
#PBS -q buhan
#PBS -V
#PBS -S /bin/bash
# 指定需要运行comsol专属的mph文件
export inputfile="fullwave_y80x60.mph"
# 自己的输出文件.mph命名
export outputfile="fullwave_y80x60_output.mph"
# 设置comsol的环境变量
EXEC=/usr/local/bin/comsol
#nodecpu=’cat /proc/cpuinfo|grep processor|wc -l’
cat $PBS_NODEFILE # > /tmp/nodefile.$$
#sed -e 's\c\ibc\g' -i /tmp/nodefile.$$
NP= `cat $PBS_NODEFILE | wc -l`
# NN=`sort -u $PBS_NODEFILE | tee /tmp/nodes.$$ | wc -l`
cd $PBS_O_WORKDIR
# 核心命令行,batch表示批量,-inputfile输入文件选项,-outputfile输出文件选项
# -batch运行日志作为记录
/opt/intel2020/icc/impi/2019.9.304/intel64/bin/mpirun -env I_MPI_FABRICS ofa
$EXEC batch -inputfile $inputfile -outputfile $outputfile -batchlog pbs_job.log
# 删除临时文件
rm -f /tmp/nodes.$$使用网页访问Slurm计算集群
网页访问地址 ood.hustcpo.com 。(已经是网页的图形化界面啦,原理和上面的命令行访问类似,自己研究研究就明白了啦?!)用户名和密码请联系服务器管理员获取。
使用文件共享在多个服务器上访问同一文件
目前已实现389服务器、489服务器和Slurm计算集群管理节点之间的文件共享。文件存储在Slurm计算集群管理节点“/public”下,389服务器和489服务器使用SFTP协议通过IB交换机进行内网访问(好长的一段字看不懂,大概意思就是这三台服务器之间的文件是共享的,而且传输速度非常快,比如你可以在Slurm计算集群上进行计算,在389服务器上直接用图形界面查看结果)。
使用方式:
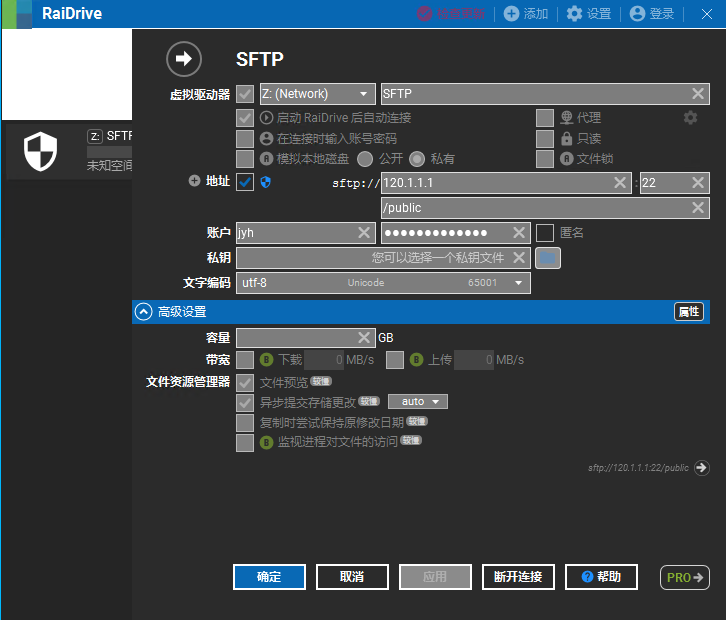
在389服务器或489服务器上使用Raidrive软件,参数设置如下,用户名和密码是Slurm计算集群上服务器管理员分配给你的用户名和密码。
进阶使用方法
如果上面的内容你已经完全理解,并且清楚地知道自己每一步都在做什么,那么你可以尝试下面的方法,来加快你的计算过程和提高仿真效率。
使用核数限制的COMSOL计算
众所周知(假的,我也不太确定),AMD的服务器级别CPU(EPYC系列)由于总线型的架构设计,导致其多核效率非常低,而COMSOL本身的多核优化也很差,所以在COMSOL仿真中经常出现 “192Core << 24Core”的情形,也就是使用单个计算服务器上的192个核心的计算速度反而不如使用24/36/48个核心的计算速度(这不是我编的,有兴趣的同学可以自己测试,也可以参考https://cn.comsol.com/support/knowledgebase/1096)。
解决办法是根据你的模型复杂度选择适当的核心数(适当是多少我也不知道,感兴趣的同学可以自己测试)。例如对于Windows平台,使用命令行窗口进入到"comsol.exe"所在的路径,并运行
cd C:\Program Files\COMSOL\COMSOL60\Multiphysics\bin\win64
comsol.exe -np 36对于Linux平台,可以在集群调度脚本中指定使用核数,也可以使用如下命令
comsol -np 36使用自定义的数学库
COMSOL和MATLAB默认Intel Math Kernel Library(Intel MKL)数学库,但对于AMD的CPU,其在科学计算上的表现并不尽如人意(我不确定,需要更多的测试)。如果你认为Intel MKL太笨了,怎么算的这么慢!而不是你自己的模型设置问题时,你可以尝试使用AMD Optimizing CPU Libraries(AOCL)数学库,这或许能帮助你加快计算速度(在某些情况下)。
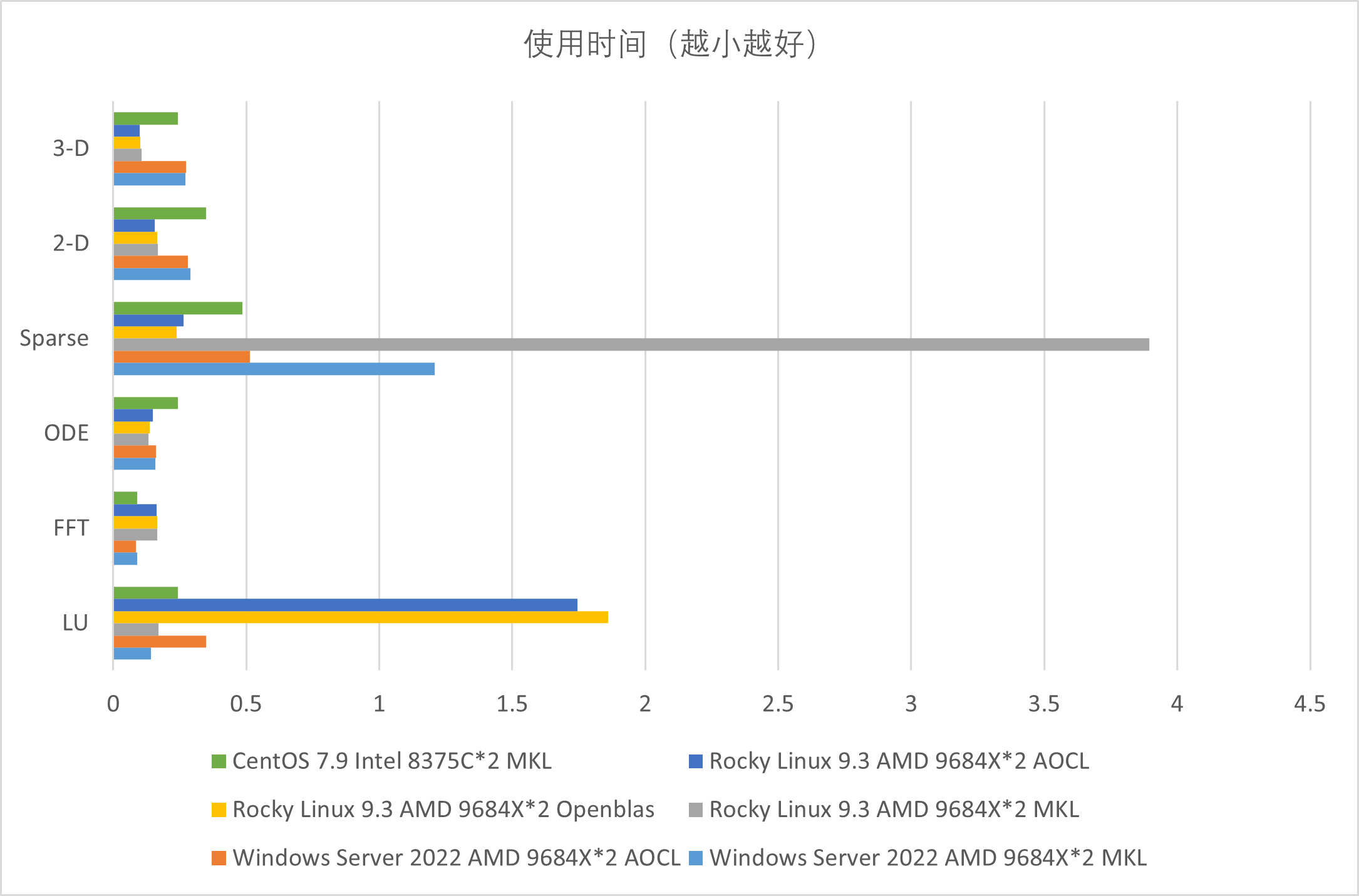
在MATLAB计算中也有类似的现象,下图是一些MATLAB的简单测试结果,不代表服务器性能,不代表个人观点,不能反映实际使用效果(叠甲):
解决办法:
在Windows平台上,在命令行进入到你要启动的程序所在的路径,如“C:\Program Files\COMSOL\COMSOL60\Multiphysics\bin\win64”或“C:\Program Files\MATLAB\R2023b\bin”,然后使用以下命令以指定数学库
set BLAS_VERSION=AOCL-LibBlis-Win-MT-dll.dll
set LAPACK_VERSION=AOCL-LibFlame-Win-MT-dll.dll
comsol.exe # 或 matlab.exe在Linux平台上,使用临时的环境变量设置,如下
export BLAS_VERSION="/opt/AMD/aocl/aocl-linux-aocc-4.2.0/aocc/lib_LP64/libblis.so"
export LAPACK_VERSION="/opt/AMD/aocl/aocl-linux-aocc-4.2.0/aocc/lib_LP64/libflame.so"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/AMD/aocl/aocl-linux-aocc-4.2.0/aocc/lib_LP64/
echo $LD_LIBRARY_PATH使用批处理扫描运行小模型多参数化情形下的COMSOL仿真
如果你的COMSOL模型很小,只占用几个G的内容,但是你需要扫描几万个参数情形下模型的不同性质,这时推荐你使用COMSOL的批处理扫描功能,这可以同时计算多个COMSOL模型。例如,使用3G的内存进行1000次计算,和使用300G内存进行10次同时处理100个模型的计算,这将大大节省你的计算时间。
参见 https://cn.comsol.com/blogs/the-power-of-the-batch-sweep/
使用parfor并行求解大型MATLAB循环
计算集群的优势在于极多的核心数和极大的共享内存,这使得你可以启用比个人电脑多的多的MATLAB并行计算池,从而加速你的并行计算。
参见 https://ww2.mathworks.cn/help/matlab/ref/parfor.html
结语
谢谢你耐心看到这里,后边没了,祝你开心 : )